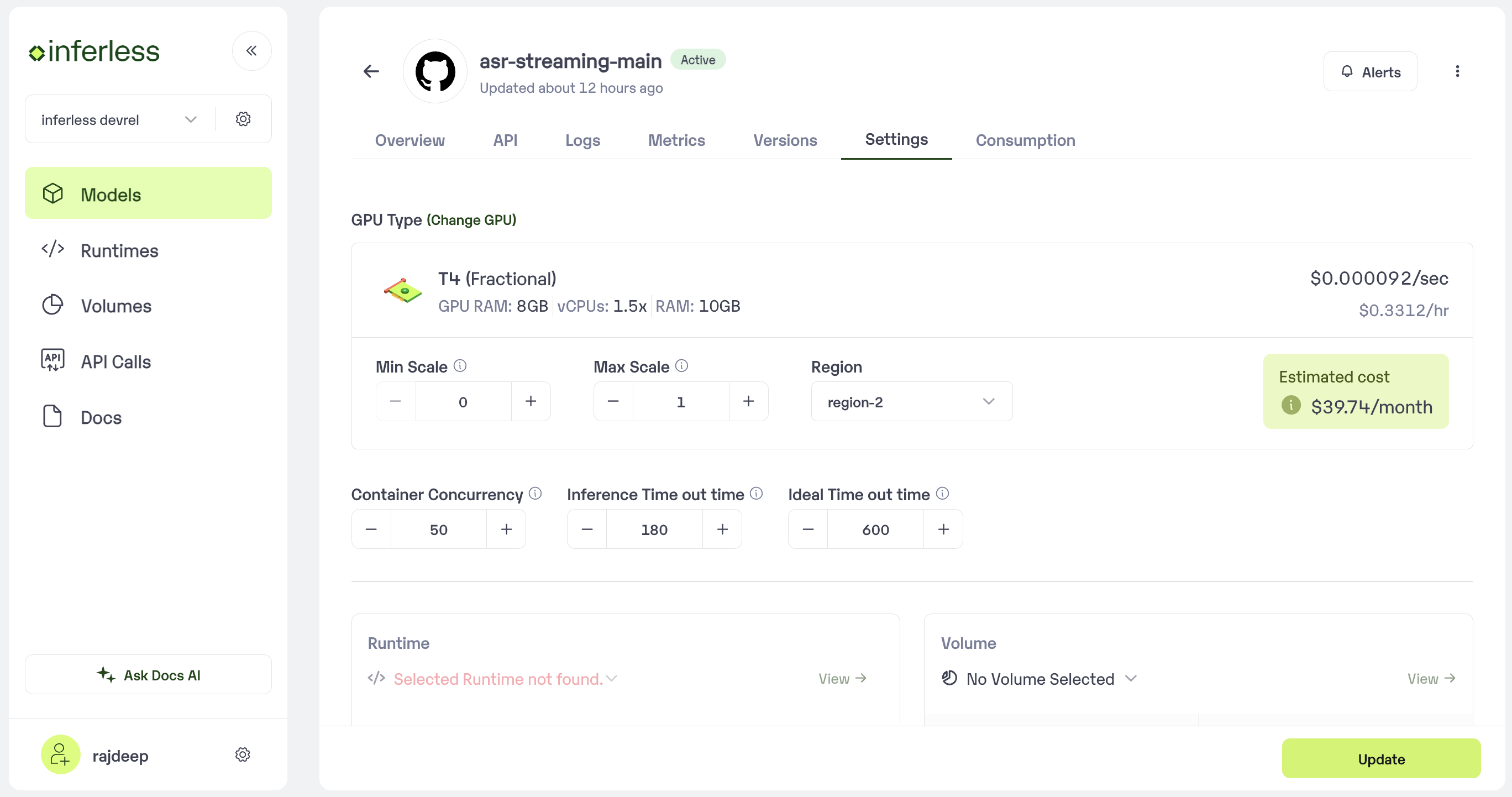
Scale Down
- Purpose: Scale-down settings determine how quickly Inferless reduces the number of idle instances (containers) to minimize costs. A faster scale-down time reduces costs by terminating idle instances sooner, but it might increase latency for new requests if instances need to be spun up frequently.
- Configuration: You typically configure Scale Down through the Inferless dashboard, setting a duration of inactivity after which an instance is terminated. Shorter durations are cost-effective but can impact performance if your workload has bursts of activity followed by periods of inactivity.
Inference Timeouts
- Purpose: Inference Timeouts define the maximum amount of time an inference request is allowed to run before it is forcibly terminated. This helps in avoiding excessive resource consumption by requests that are stuck or taking too long, ensuring resources are available for other requests.
- Configuration: Set the timeout based on the expected duration of your inference tasks. Consider the complexity of the model and the size of the input data. Configuring this setting usually involves specifying a timeout value (in seconds) in the Inferless dashboard. It’s crucial to balance between allowing enough time for legitimate requests to complete and preventing resource hogging.
Container Concurrency
- Purpose: Container Concurrency settings control the number of concurrent requests a single container can handle. Adjusting this setting helps in managing the trade-off between latency and resource utilization. A lower concurrency level can improve latency at the cost of higher resource usage (since more containers may be spun up to handle incoming requests), whereas a higher concurrency level can reduce resource usage but might increase latency if the container becomes a bottleneck.
- Configuration: Determine the optimal concurrency level based on your model’s resource requirements and the expected request load. Configure this setting in the Inferless platform, either through the dashboard, by specifying the maximum number of concurrent requests per container.
Practical Steps:
- Access Inferless Dashboard: Start by logging into the Inferless dashboard and click on the model.
- Navigate to Model Settings: Look for the settings or configuration section where you can find options for Scale Down, Inference Timeouts, and Container Concurrency.
- Adjust Settings:
- For Scale Down, set the idle time before an instance is terminated.
- For Inference Timeouts, specify the maximum allowed duration for an inference request.
- For Container Concurrency, set the maximum number of concurrent requests per container.
- Save Changes: After adjusting the settings, save your changes. It might be beneficial to monitor the performance and cost implications and adjust these settings as needed.