Method A: Configure using Inferless Platform
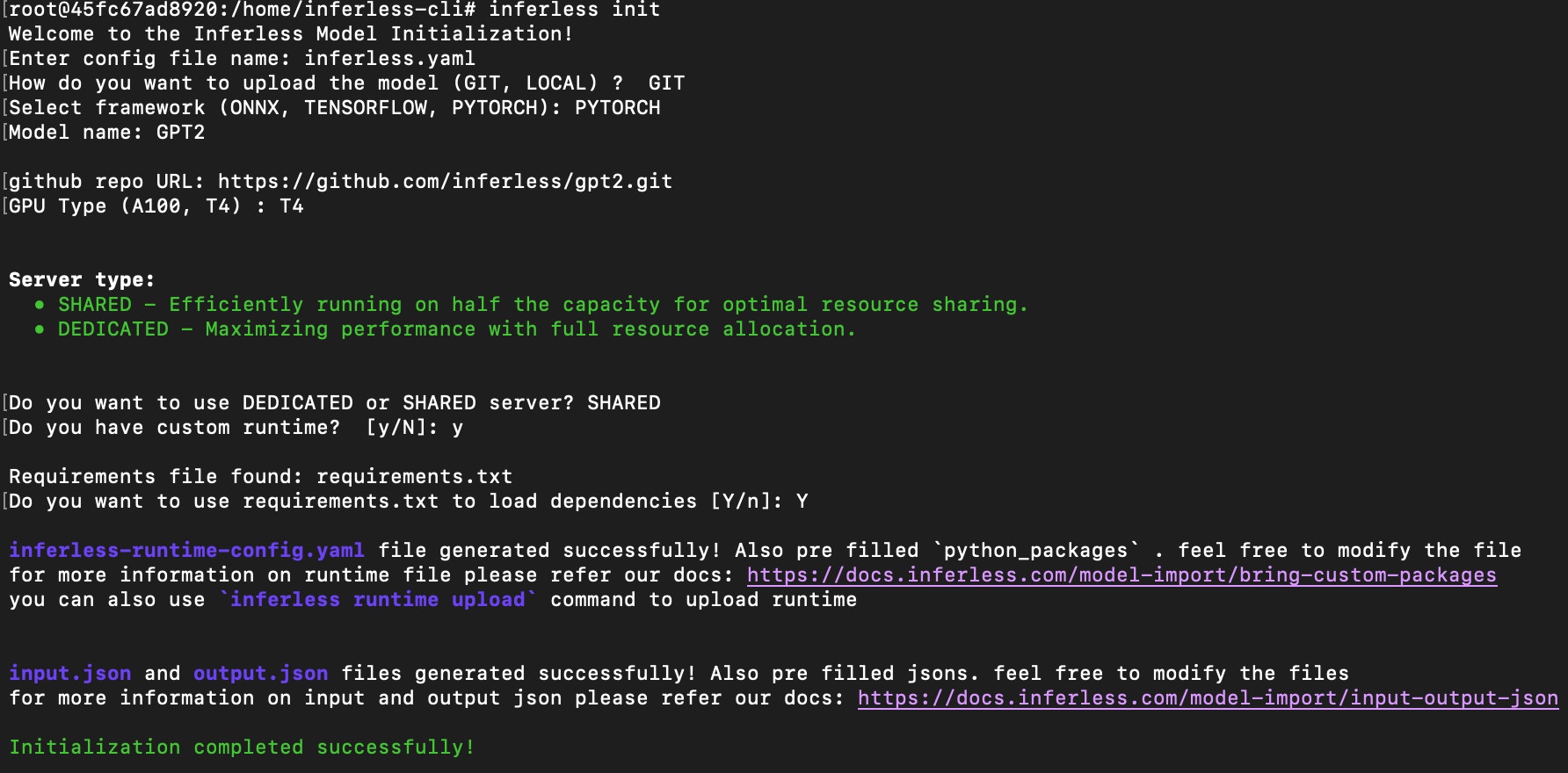
In the model configuration you are asked to choose your desired runtime and machine configurations.- We suggest using ONNX for the most optimal results. If we are unable to convert to ONNX, we will use your native framework and load the model. If you would like to keep the same framework as your input model, you can select it from the dropdown.
- Choose the type of machine, and specify the minimum and maximum number of replicas for deploying your model.
-
Choose the Minimum and Maximum replicas that you would need for your model
- Min replica -
- Max replica -
-
In case you would like to set up
Automatic rebuildfor your model, enable it- You would need to set up a web hookwebhook for this method. Click here for more details.
Method B: Configure using Inferless CLI
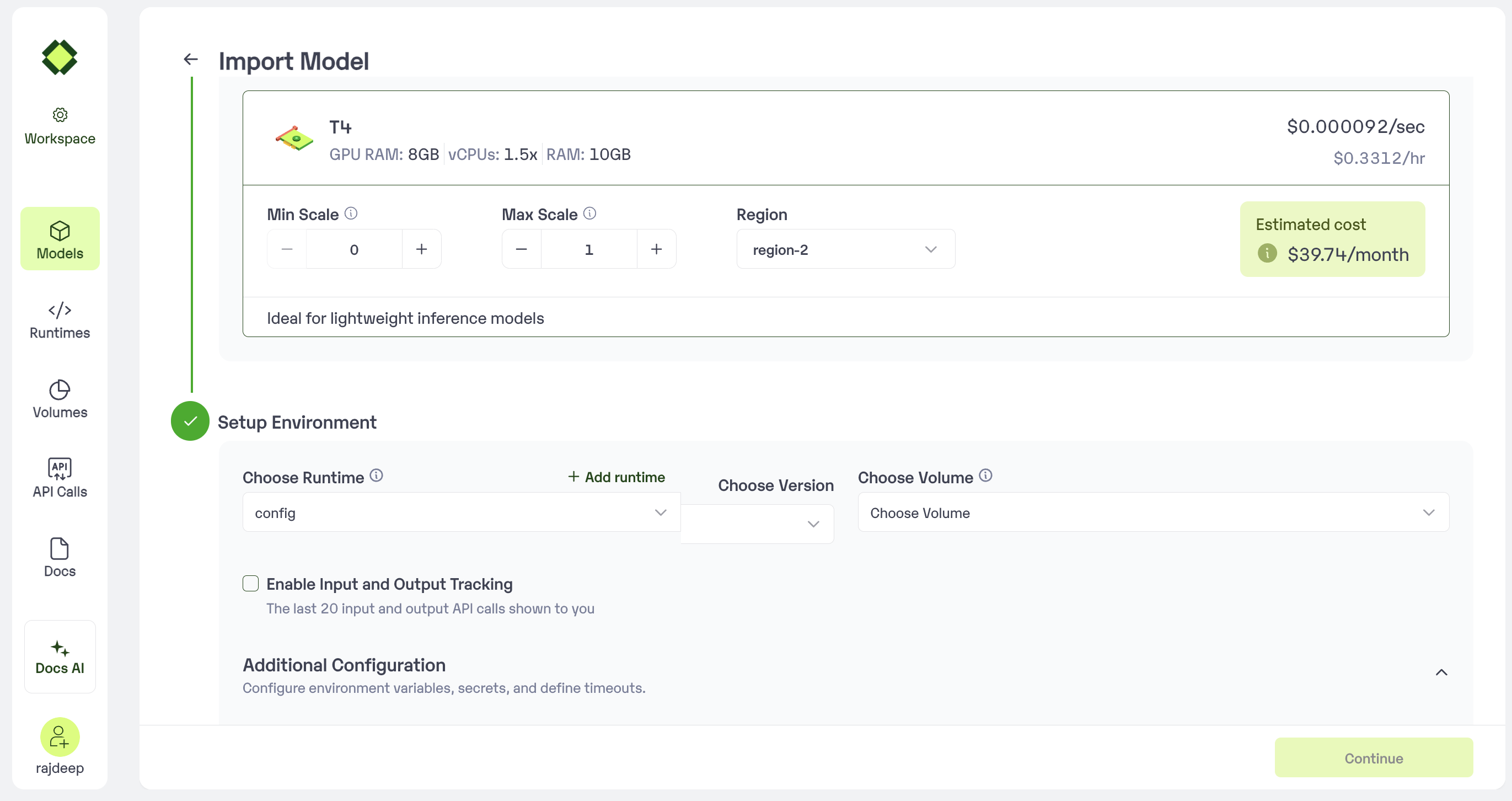
To start with the inference configuration process, first you have to run this commandinferless init. Follow the following steps for configuration:
- Enter the inference configuration file name: You are required to give the name to the inference file.
- Select how you want to upload your model: You have two options, either you can upload your model from the local or you can upload via GitHub.
- Enter your model name: You can give any name to your model.
- Enter the github repo link: You have to pass the github repo link which will have the required files.
- Select the type of GPU: We provide two type of GPU, A100 and T4.
- Select the type of the server: Users can select a DEDICATED server, or can opt for a SHARED server which provide 50% of the GPU machine.
- Select if you want to use your custom runtime: You can pass your requirements.txt file and it will create the inferless-runtime-config.yaml file. If you required any software packages then you can update the runtime file.
app.py. Now you are ready to deploy your model.