- ** Sequentical Processing with Queue**
- ** Batch Processing with Queue **
Sequential Processing with Queue
This is the simplest way to process multiple requests with the same replica. In this method, the requests are processed sequentially by the same replica. This is useful when you have task that takes less time to process. To configure this you can go to Model Import -> Settings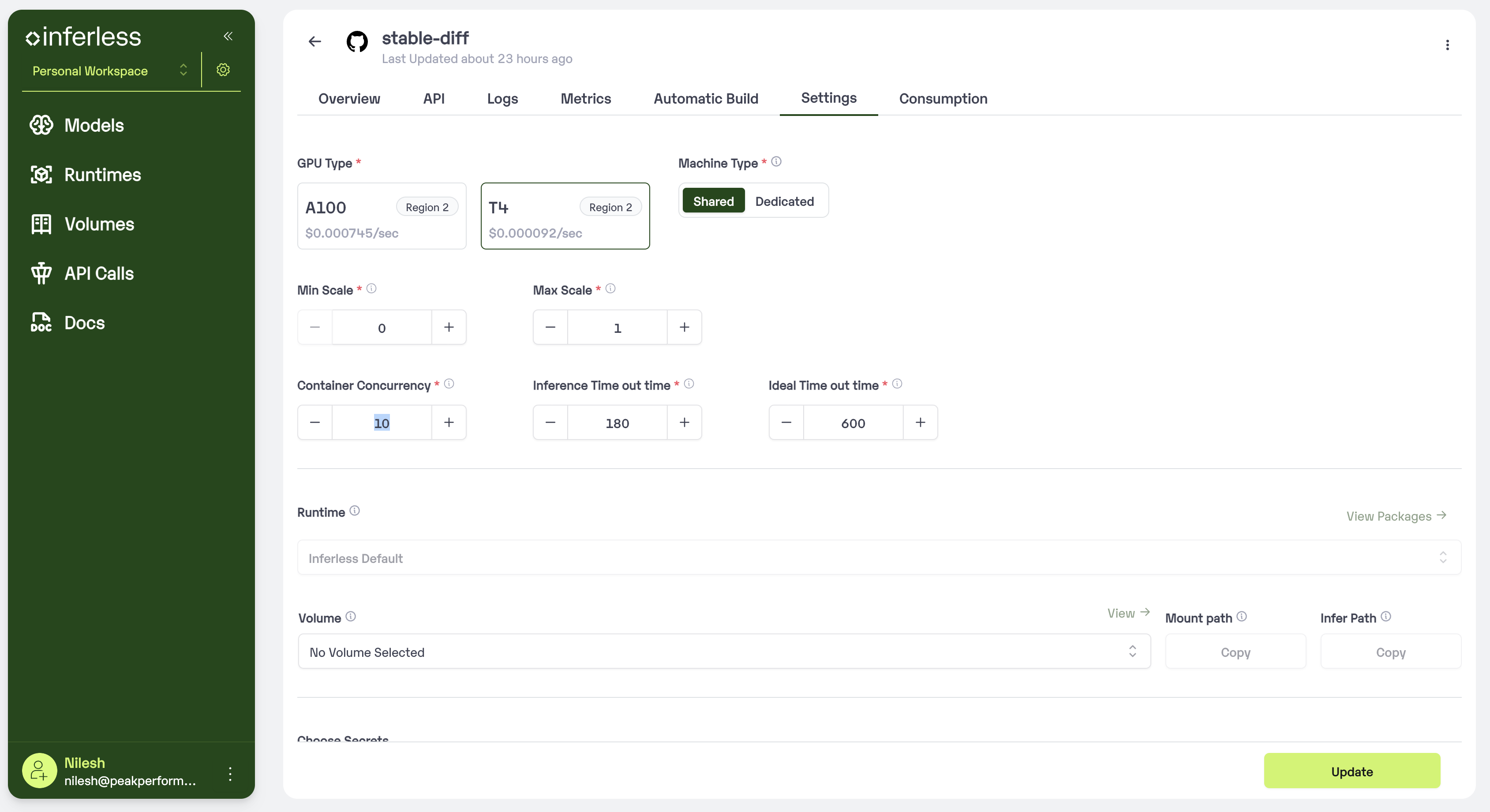
Batch Processing with Queue
This method processes the requests in batches by the same replica. This is useful when you have tasks that take longer to process and want to process multiple requests simultaneously.Step 1: Preparing the model to handle concurrent requests
Define the BATCH_SIZE and BATCH_WINDOW in the input_schema.py input_schema.pyStep 2: Configuring the model to handle concurrent requests
Go to Model Import -> Settings