Introduction
Mixtral-8x7B is a Sparse Mixture of Experts (SMoE) with 46.7B parameters and one of the best open large language models (LLM). Mixtral was trained with a context size of 32k tokens and it outperforms or matches Llama-2 70B and GPT-3.5 across all evaluated benchmarks. Mixtral and Mistral 7B share the same structure, but Mixtral’s layers consist of 8 feedforward blocks or experts. In each layer, a router network chooses two experts to handle the current state of a token and merges their outputs. Although each token interacts with only two experts, the chosen ones can vary at each step. This design allows each token to access a total of 47B parameters, yet during inference, only 13B of these parameters are actively utilized.Our Observations
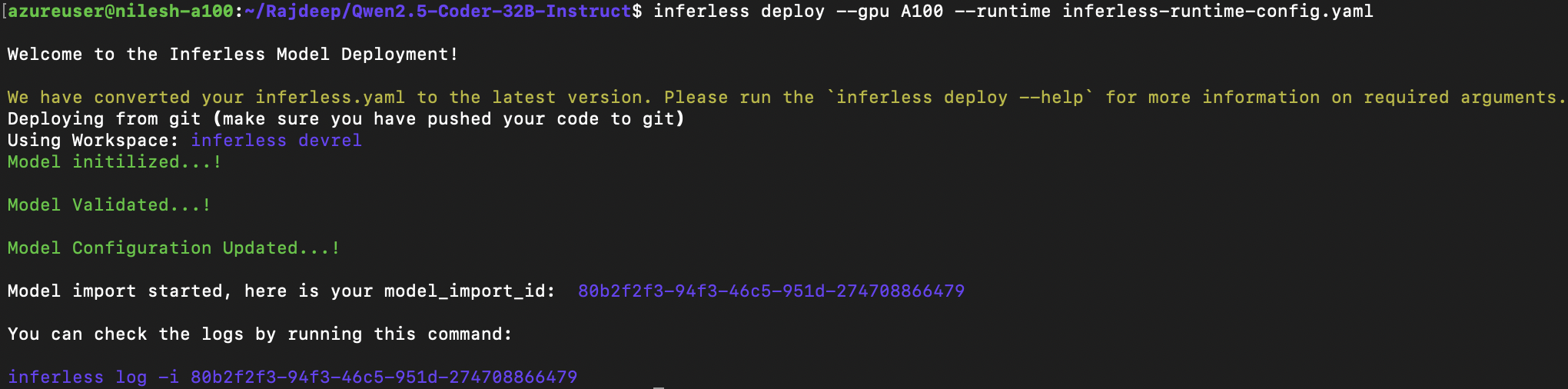
We experimented Mixtral 8x7B with various configurations using PyTorch, vLLM, AutoGPTQ, and HQQ. For all our experiments, we have set the max-token to 256 and done all experiments on a single A100(80GB) GPU machine. For fast inference, we took advantage of PyTorch(nightly) optimizations (GitHub repository). We have deployed an 8-bit quantize model and got an average token generation rate of 52.03 token/sec. We also tried deploying a 4-bit quantized model via vLLM(0.2.7), Auto-GPTQ(0.6.0) and HQQ(0.1.2) as mentioned in our observations below:Defining Dependencies
We are using gpt-fast(GitHub repository from PyTorch Labs), written in native PyTorch. Install the PyTorch nightly, Sentencepiece and Huggingface_hub.Constructing the GitHub/GitLab Template
First, to quickly construct the GitHub/GitLab template, copy all the files from this Inferless repository. After that, you can create the app.py and inferless-runtime-config.yaml.Create the class for inference
In the app.py we will define the class and import all the required functions-
def initialize: In this function, you will download and initialize your model. Here we have used themodel_initializefunction from the get_model script, this loads and initialize the model. You can customize theget_modelscript according to your requirements. Also in this function, you can define any variable that you want to use during inference. -
def infer: This function gets called for every request that you send. Here you can define all the steps that are required for the inference. You can also pass custom values for inference and pass it throughinputs(dict)parameters. -
def finalize: This function cleans up all the allocated memory.
Creating the Custom Runtime
This is a mandatory step where we allow the users to upload their custom runtime through inferless-runtime-config.yaml.Method A: Deploying the model on Inferless Platform
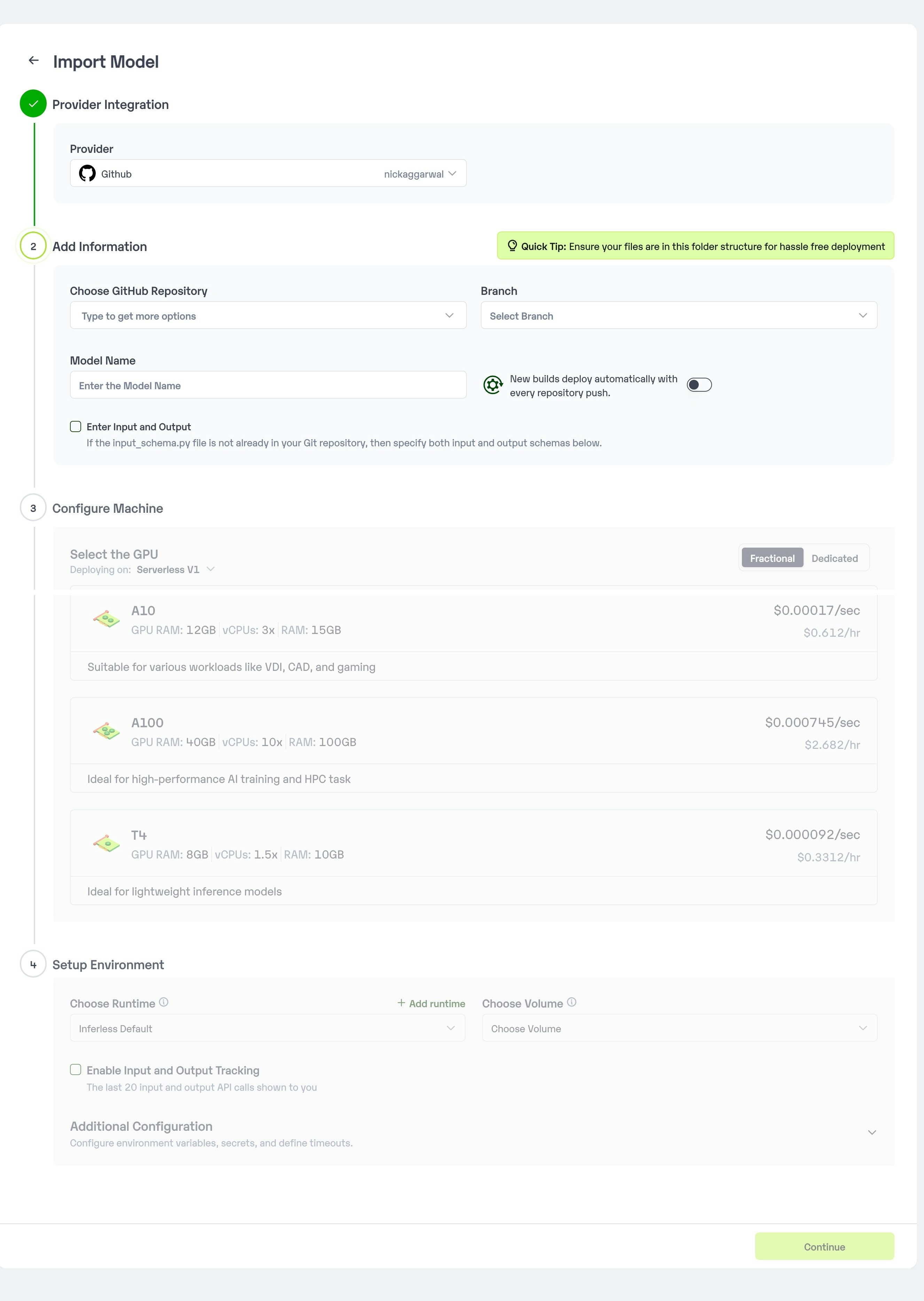
Inferless supports multiple ways of importing your model. For this tutorial, we will use GitHub.Step 1: Login to the inferless dashboard can click on Import model button
Navigate to your desired workspace in Inferless and Click onAdd a custom model button that you see on the top right. An import wizard will open up.
Step 2: Follow the UI to complete the model Import
- Select the GitHub/GitLab Integration option to connect your source code repository with the deployment environment.
- Navigate to the specific GitHub repository that contains your model’s code. Here, you will need to identify and enter the name of the model you wish to import.
- Choose the appropriate type of machine that suits your model’s requirements. Additionally, specify the minimum and maximum number of replicas to define the scalability range for deploying your model.
- Optionally, you have the option to enable automatic build and deployment. This feature triggers a new deployment automatically whenever there is a new code push to your repository.
- If your model requires additional software packages, configure the Custom Runtime settings by including necessary pip or apt packages. Also, set up environment variables such as Inference Timeout, Container Concurrency, and Scale Down Timeout to tailor the runtime environment according to your needs.
- Wait for the validation process to complete, ensuring that all settings are correct and functional. Once validation is successful, click on the “Import” button to finalize the import of your model.
Step 3: Wait for the model build to complete usually takes ~5-10 minutes
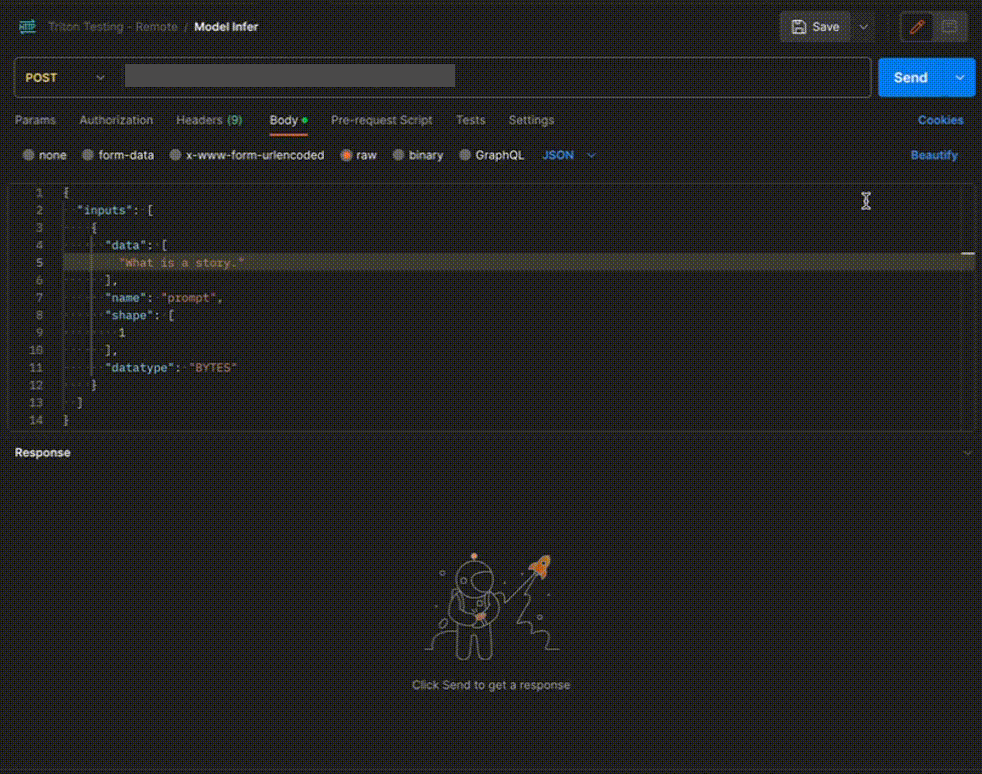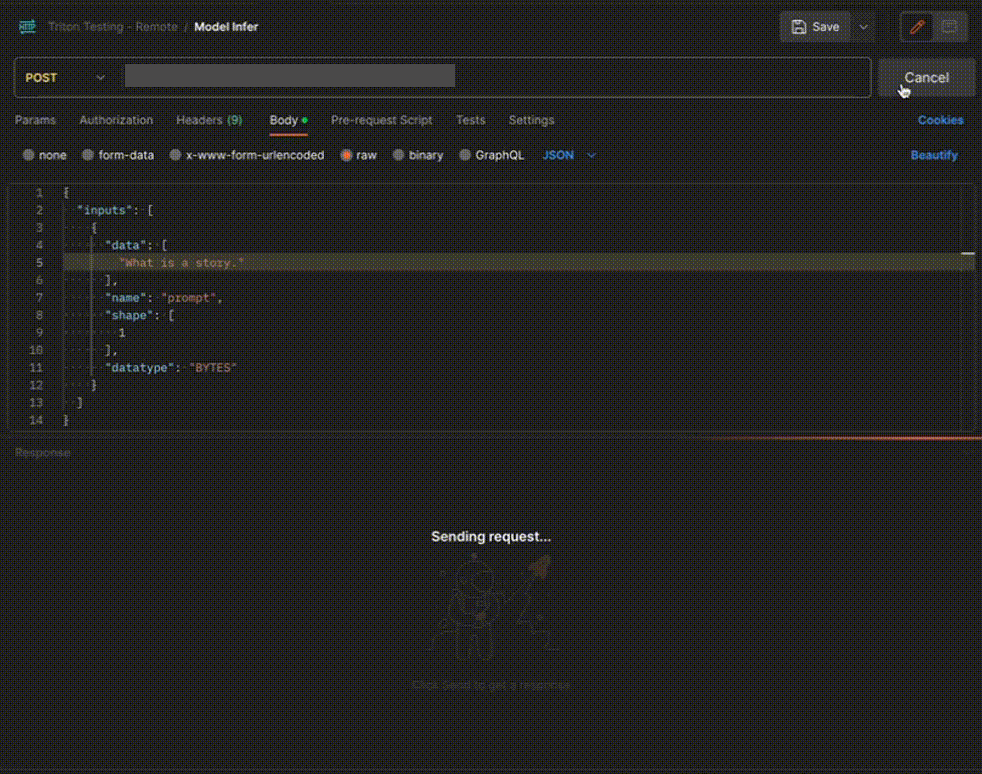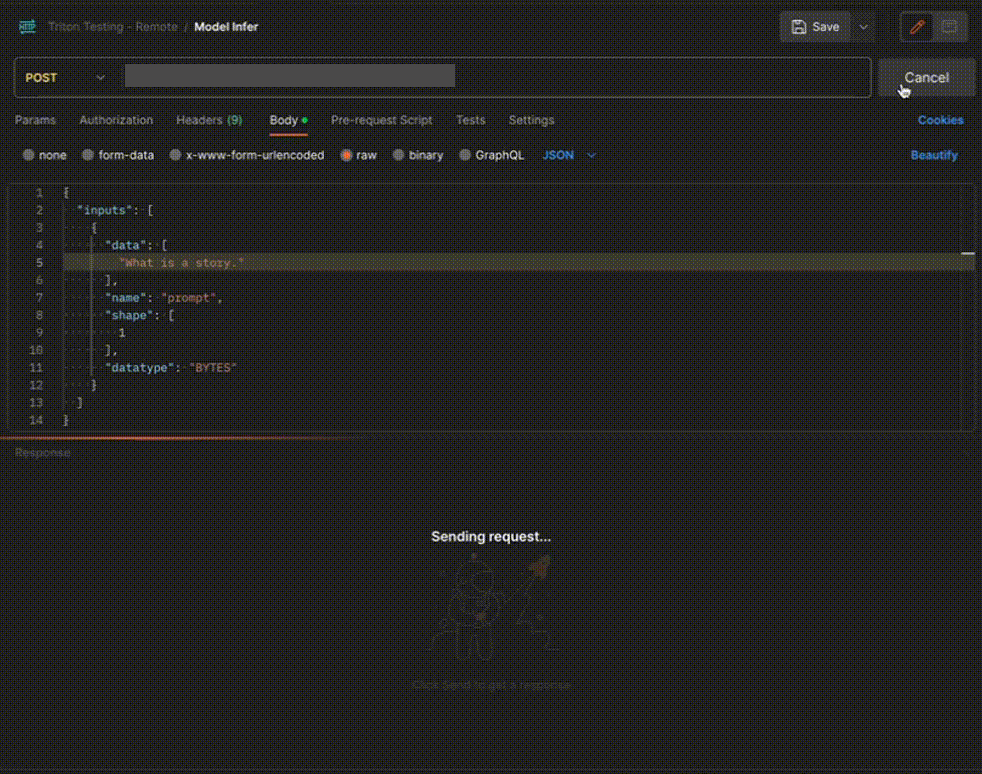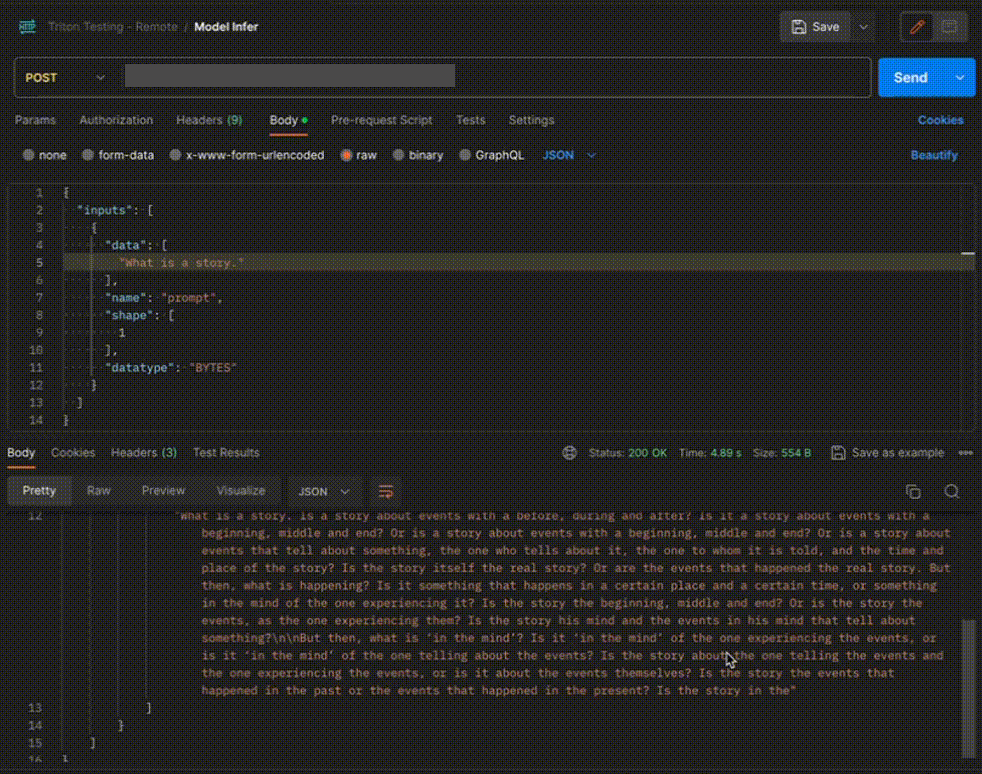
Step 4: Use the APIs to call the model
Once the model is in ‘Active’ status you can click on the ‘API’ page to call the modelHere is the Demo:
Method B: Deploying the model on Inferless CLI
Inferless allows you to deploy your model using Inferless-CLI. Follow the steps to deploy using Inferless CLI.Clone the repository of the model
Let’s begin by cloning the model repository:Deploy the Model
To deploy the model using Inferless CLI, execute the following command:--gpu A100: Specifies the GPU type for deployment. Available options includeA10,A100, andT4.--runtime inferless-runtime-config.yaml: Defines the runtime configuration file. If not specified, the default Inferless runtime is used.