Key Components of the Application
In the process of building this application, we’ll we will utilize three distinct types of models:- Automatic Speech Recognition Model: This model facilitates the conversion of spoken words into text. We’ll harness the power of the Whisper large v3 model for this task.
- Text Generation Model: This model is crucial for formulating responses to user queries, and plays a vital role in the conversational flow. Our choice for this task is the Mistral 7B Instruct v0.2 model.
- Text-to-Audio Model: To provide a seamless conversational experience, the output generated by the text generation model will be transformed into speech using Bark model.
Crafting Your Application
This tutorial guides you through the creation process of a voice conversational chatbot application. It leverages advanced technologies such as Bark, Faster-Whisper, Transformers, and Inferless.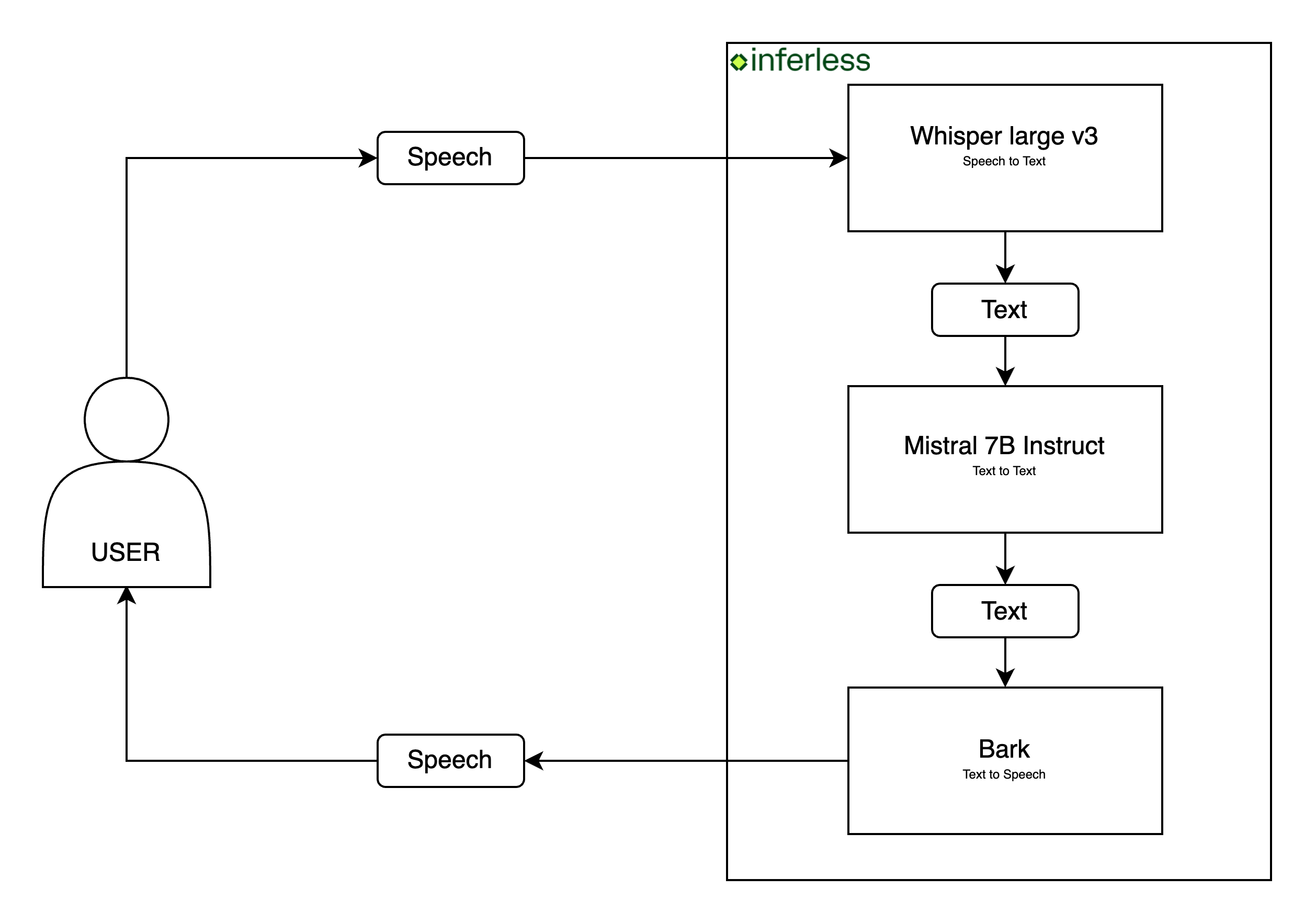
Core Development Steps
Speech-to-Speech Generation
- Objective: Accept user voice as a input and generate a response in audio.
- Action: Implement a Python class (InferlessPythonModel) that handles the entire speech-to-speech generation process, including input handling, models integration, and audio generation.
Setting up the Environment
Dependencies:- Objective: Ensure all necessary libraries are installed.
- Action: Run the command below to install dependencies:
Deploying Your Model with Inferless CLI
Inferless allows you to deploy your model using Inferless-CLI. Follow the steps to deploy using Inferless CLI.Clone the repository of the model
Let’s begin by cloning the model repository:Deploy the Model
To deploy the model using Inferless CLI, execute the following command:--gpu A100: Specifies the GPU type for deployment. Available options includeA10,A100, andT4.--runtime inferless-runtime-config.yaml: Defines the runtime configuration file. If not specified, the default Inferless runtime is used.
Demo of the Voice Conversational Chatbot.
Alternative Deployment Method
Inferless also supports a user-friendly UI for model deployment, catering to users at all skill levels. Refer to Inferless’s documentation for guidance on UI-based deployment.Choosing Inferless for Deployment
Deploying your Voice Conversational Chatbot application with Inferless offers compelling advantages, making your development journey smoother and more cost-effective. Here’s why Inferless is the go-to choice:- Ease of Use: Forget the complexities of infrastructure management. With Inferless, you simply bring your model, and within minutes, you have a working endpoint. Deployment is hassle-free, without the need for in-depth knowledge of scaling or infrastructure maintenance.
- Cold-start Times: Inferless’s unique load balancing ensures faster cold-starts. Expect around 28.60 seconds to process each queries, significantly faster than many traditional platforms.
- Cost Efficiency: Inferless optimizes resource utilization, translating to lower operational costs. Here’s a simplified cost comparison:
Scenario 1
You are looking to deploy a Voice Conversational Chatbot application for processing 100 queries.Parameters:
- Total number of queries: 100 daily.
- Inference Time: All models are hypothetically deployed on A100 80GB, taking 28.60 seconds of processing time and a cold start overhead of 20.72 seconds.
- Scale Down Timeout: Uniformly 60 seconds across all platforms, except Hugging Face, which requires a minimum of 15 minutes. This is assumed to happen 100 times a day.
- Inference Duration:
Processing 100 queries and each takes 28.60 seconds
Total: 100 x 28.60 = 2860 seconds (or approximately 0.79 hours) - Idle Timeout Duration:
Post-processing idle time before scaling down: (60 seconds - 28.60 seconds) x 100 = 3140 seconds (or 0.87 hours approximately) - Cold Start Overhead:
Total: 100 x 20.72 = 2072 seconds (or 0.58 hours approximately)
Total Billable Hours with Inferless: 2.24 hours
Scenario 2
You are looking to deploy a Voice Conversational Chatbot application for processing 1000 queries per day.Key Computations:
- Inference Duration:
Processing 1000 queries and each takes 28.60 seconds Total: 1000 x 28.60 = 28600 seconds (or approximately 7.94 hours) - Idle Timeout Duration:
Post-processing idle time before scaling down: (60 seconds - 28.60 seconds) x 100 = 3140 seconds (or 0.87 hours approximately) - Cold Start Overhead:
Total: 100 x 20.72 = 2072 seconds (or 0.58 hours approximately)
Total Billable Hours with Inferless: 9.39 hours
Pricing Comparison for all the Scenario
| Scenarios | AWS SageMaker Cost | Inferless Cost |
|---|---|---|
| 100 requests/day | $28.8 (24 hours billed at $1.22/hour) | $2.73 (2.24 hours billed at $1.22/hour) |
| 1000 requests/day | $28.8 (24 hours billed at $1.22/hour) | $11.46 (9.39 hours billed at $1.22/hour) |
Please note that we have utilized the A100(80 GB) GPU for model benchmarking purposes, while for pricing comparison, we referenced the A10G GPU price from both platforms. This is due to the unavailability of the A100 GPU in SageMaker. Also, the above analysis is based on a smaller-scale scenario for demonstration purposes. Should the scale increase tenfold, traditional cloud services might require maintaining 2-4 GPUs constantly active to manage peak loads efficiently. In contrast, Inferless, with its dynamic scaling capabilities, adeptly adjusts to fluctuating demand without the need for continuously running hardware.