Key Components of the Application
-
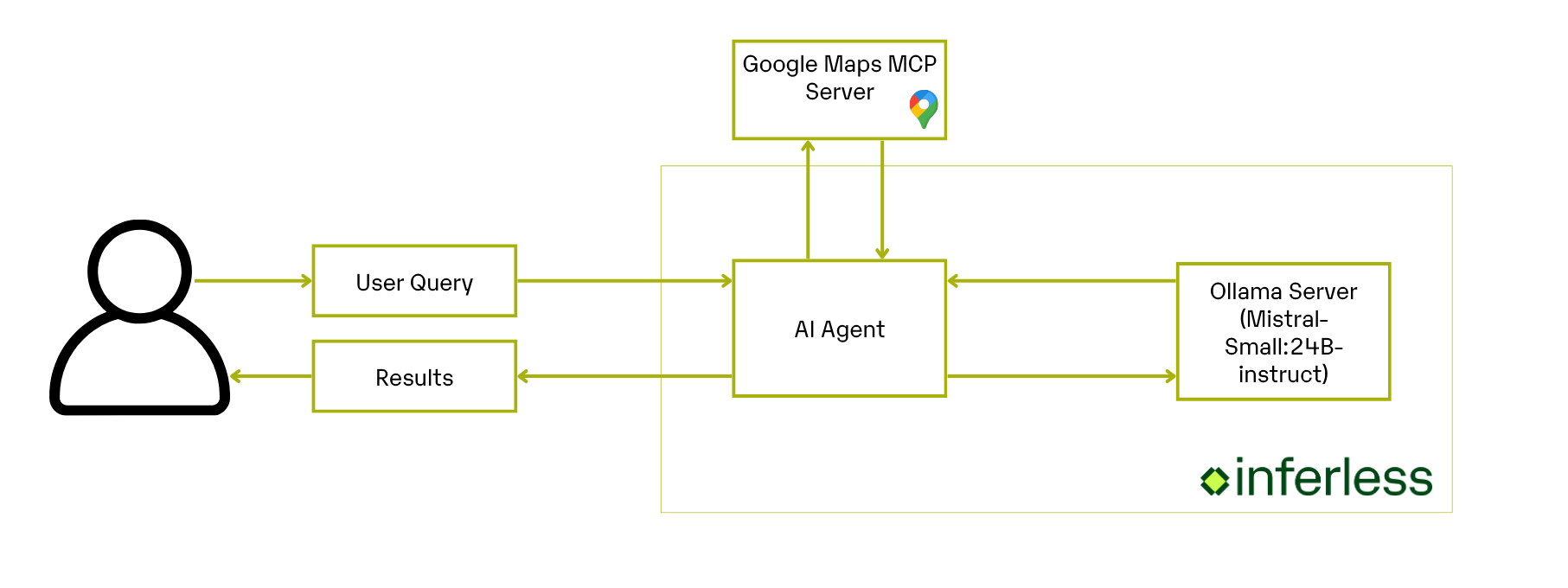
MCP Google Maps Tools: Provides a standardized interface for querying Google Maps (via
@modelcontextprotocol/server-google-maps) over stdio. - OllamaManager: Manages the lifecycle of your local Ollama LLM server: start, readiness checks and model pulls.
- LangChain & Inferless Integration: Use the agent’s workflow which takes your question, uses the right tools to gather the information, and then sends that info to the language model for an answer.
- Prompt Engineering: Defines strict system and user prompts that transform raw place-search results into a clean, under-120-word markdown summary.
Crafting Your Application
- User Query Intake: Collect a natural-language query, e.g. “Find me tea shops in HSR Layout, Bangalore with good reviews.”
-
Maps Data Retrieval: Use
stdio_client+ MCP‐Google‐Maps server to fetch place data from Google’s API. - Data Extraction & Formatting: Parse the returned messages for the tool call, extract the JSON content, and prepare it for summarization.
- Response Generation: Pass the cleaned place data into your Mistral-Small instruct model running on Ollama, with a tightly constrained prompt template.
Core Development Steps
1. Manage Your Local Ollama Server
Objective: Set up and control your local Ollama server, making sure your LLM is always ready to respond. Action: Use the providedOllamaManager class to easily:
- Start and verify your Ollama server.
- Download and verify models automatically.
- Safely shut down the server when your app closes.
2. Build Your Google Maps Agent
Objective: Create an assistant that processes user requests, fetches Google Maps data, and generates concise, readable responses. Action: In yourapp.py script, set up a clear workflow that:
- Takes user queries (e.g., “Find tea shops in Bangalore”).
- Uses MCP Google Maps integration to fetch accurate, detailed information.
- Parses and simplifies the retrieved data.
- Sends the formatted information to your locally hosted Ollama LLM.
- Generates a neat, markdown-formatted summary that’s easy for users to read.
Setting up the Environment
Here’s how to set up all the build-time and run-time dependencies for your Google Maps agent:1. Build-Time Configuration
Before anything else, make sure your machine has these libraries and software packages installed.-
Python libraries:
-
Ollama LLM Server: Download and install the Ollama standalone binary:
-
Node.js & MCP Google Maps Server: The MCP tools server runs on Node.js. Install Node.js LTS via the official NodeSource setup.
Deploying Your Model with Inferless CLI
Inferless allows you to deploy your model using Inferless-CLI. Follow the steps to deploy using Inferless CLI.Clone the repository of the model
Let’s begin by cloning the model repository:Deploy the Model
To deploy the model using Inferless CLI, execute the following command:--gpu A100: Specifies the GPU type for deployment. Available options includeA10,A100, andT4.--runtime inferless-runtime-config.yaml: Defines the runtime configuration file. If not specified, the default Inferless runtime is used.
Demo of the Google Maps Agent.
Alternative Deployment Method
Inferless also supports a user-friendly UI for model deployment, catering to users at all skill levels. Refer to Inferless’s documentation for guidance on UI-based deployment.Choosing Inferless for Deployment
Deploying your Google Maps Agent application with Inferless offers compelling advantages, making your development journey smoother and more cost-effective. Here’s why Inferless is the go-to choice:- Ease of Use: Forget the complexities of infrastructure management. With Inferless, you simply bring your model, and within minutes, you have a working endpoint. Deployment is hassle-free, without the need for in-depth knowledge of scaling or infrastructure maintenance.
- Cold-start Times: Inferless’s unique load balancing ensures faster cold-starts.
- Cost Efficiency: Inferless optimizes resource utilization, translating to lower operational costs. Here’s a simplified cost comparison:
Scenario
You are looking to deploy a Google Maps Agent application for processing 100 queries.Parameters:
- Total number of queries: 100 daily.
- Inference Time: All models are hypothetically deployed on A100 80GB, taking 22.45 seconds to process a request and a cold start overhead of 4.86 seconds.
- Scale Down Timeout: Uniformly 60 seconds across all platforms, except Hugging Face, which requires a minimum of 15 minutes. This is assumed to happen 100 times a day.
- Inference Duration:
Processing 100 queries and each takes 22.45 seconds
Total: 100 x 22.45 = 2245 seconds (or approximately 0.62 hours) - Idle Timeout Duration:
Post-processing idle time before scaling down: (60 seconds - 22.45 seconds) x 100 = 3755 seconds (or 1.04 hours approximately) - Cold Start Overhead:
Total: 100 x 4.86 = 486 seconds (or 0.14 hours approximately)
Total Billable Hours with Inferless: 1.8 hours
By opting for Inferless, you can achieve up to 93.75% cost savings.
Please note that we have utilized the A100(80 GB) GPU for model benchmarking purposes, while for pricing comparison, we referenced the A10G GPU price from both platforms. This is due to the unavailability of the A100 GPU in SageMaker. Also, the above analysis is based on a smaller-scale scenario for demonstration purposes. Should the scale increase tenfold, traditional cloud services might require maintaining 2-4 GPUs constantly active to manage peak loads efficiently. In contrast, Inferless, with its dynamic scaling capabilities, adeptly adjusts to fluctuating demand without the need for continuously running hardware.