Understanding Retrieval-Augmented Generation (RAG)
Before diving in, let’s briefly understand the technology behind our app. Retrieval-Augmented Generation (RAG) combines the power of large language models with external data sources to enhance response accuracy and context. It involves:- Retrieval: Fetching relevant data in response to queries.
- Augmentation: Enhancing the language model’s knowledge with this data.
- Generation: Producing accurate, context-aware responses.
Crafting Your Application
This tutorial is structured to ease you into creating a PDF Q&A application using technologies like LangChain, Pinecone, and Inferless.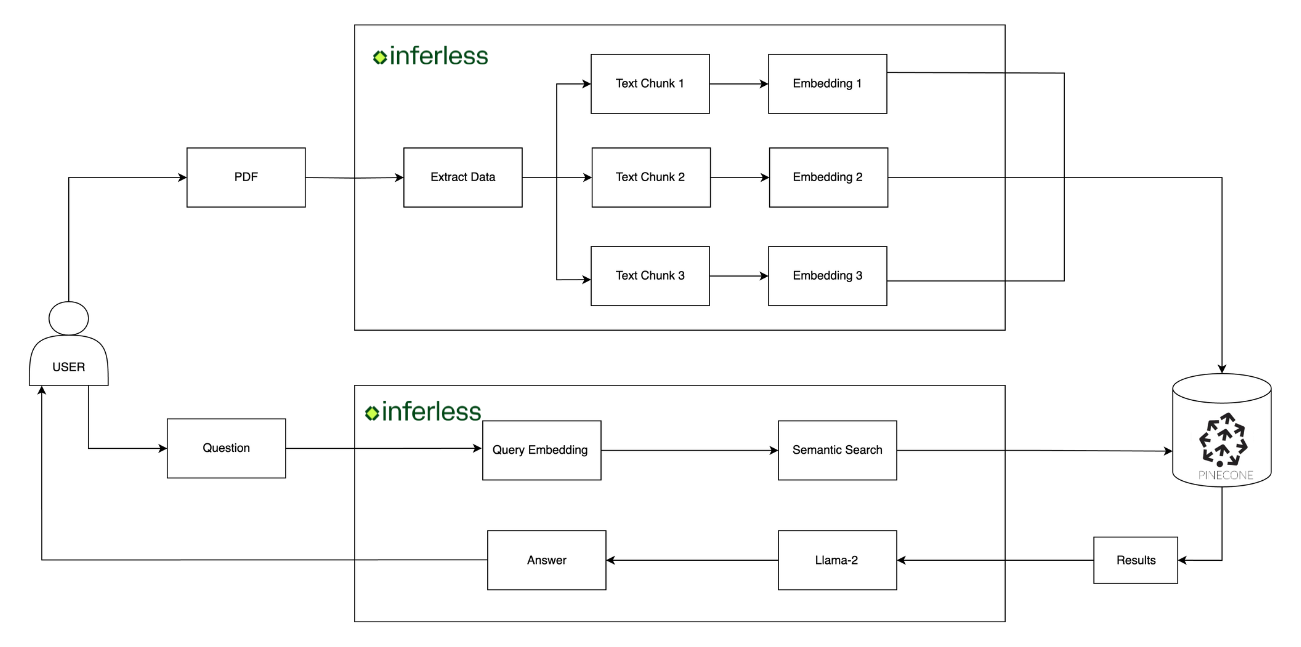
Obtaining your Pinecone API Key
To seamlessly integrate Pinecone, a fully managed vector database, into our application, securing an API Key is essential. Here’s a simplified guide to getting started:- Registration: Begin by signing up on the Pinecone platform using your email address. Pinecone serves as the backbone for managing and querying vector data efficiently.
- Index Creation: Once registered, proceed to create an index on Pinecone. Remember to note its name; this will be crucial for configuring your application.
- API Key Access: With your index ready, navigate to the API Keys section, easily found in the Pinecone dashboard’s left sidebar.
- API Key Retrieval: Copy the API Key presented here. This key will authenticate your application’s requests to Pinecone, enabling secure and efficient data operations.
The next phase involves preparing your deployment environment. While this guide focuses on Inferless for its simplicity and efficiency in serverless deployments, you’re encouraged to select the platform that best fits your project needs.
Core Development Steps
PDF Upload Functionality:
- Objective: Establish a process for uploading and managing PDFs, utilizing LangChain for document loading and Pinecone for efficient data indexing.
- Action: Implement a Python class for PDF management. Refer to our GitHub example for detailed code.
Integrating Q&A Functionality:
- Objective: Enable the application to process user queries and extract answers from PDFs, employing the RAG technique.
- Action: Develop a Python class to merge embeddings with LangChain’s retrieval capabilities and the Llama-2 7B model for answer generation. Our GitHub repository provides a comprehensive example.
Setting up the Environment
Dependencies:- Objective: Ensure all necessary libraries are installed.
- Action: Run the command below to install dependencies:
Organizing Your Application:
- Structure: Divide your application into two main parts for better modularity and maintenance:
- PDF Upload Component: Handles the uploading and initial processing of PDF documents. See GitHub Repository.
- Q&A Component: Manages the extraction of information and answering of user queries from PDFs. See GitHub Repository.
Deploying Your Model with Inferless CLI
PDF Upload Deployment:
Inferless allows you to deploy your model using Inferless-CLI. Follow the steps to deploy using Inferless CLI.Clone the repository of the model
Let’s begin by cloning the model repository:Deploy the Model
To deploy the model using Inferless CLI, execute the following command:PDF Q&A Deployment:
Inferless allows you to deploy your model using Inferless-CLI. Follow the steps to deploy using Inferless CLI.Clone the repository of the model
Let’s begin by cloning the model repository:Deploy the Model
To deploy the model using Inferless CLI, execute the following command:--gpu A100: Specifies the GPU type for deployment. Available options includeA10,A100, andT4.--runtime inferless-runtime-config.yaml: Defines the runtime configuration file. If not specified, the default Inferless runtime is used.
Alternative Deployment Method
Inferless also supports a user-friendly UI for model deployment, catering to users at all skill levels. Refer to Inferless’s documentation for guidance on UI-based deployment.Choosing Inferless for Deployment
Deploying your PDF Q&A app with Inferless offers compelling advantages, making your development journey smoother and more cost-effective. Here’s why Inferless is the go-to choice:- Ease of Use: Forget the complexities of infrastructure management. With Inferless, you simply bring your model, and within minutes, you have a working endpoint. Deployment is hassle-free, without the need for in-depth knowledge of scaling or infrastructure maintenance.
- Cold-start Times: Inferless’s unique load balancing ensures faster cold-starts. Expect around 6.20 seconds for PDF uploads and 11.7 seconds for Q&A functionalities, significantly faster than many traditional platforms.
- Cost Efficiency: Inferless optimizes resource utilization, translating to lower operational costs. Here’s a simplified cost comparison:
PDF Upload:
Assumptions:- 100 documents uploaded daily
- Each document takes 20 seconds of processing time (inference)
- Additional time considerations include a 6.20-second cold start for each upload
Total Active Processing Time: 100 documents * 20 seconds each = 2000 seconds (or approximately 0.55 hours)
Cold Start Overhead: 100 uploads * 6.20 seconds each = 620 seconds (or 0.17 hours)
Idle Time Between Uploads: ((60 seconds - 20 seconds) * 100) / 3600 = approximately 1.1 hours
Total Billable Hours with Inferless: 1.82 hours
Q&A for PDFs
Assumptions:- 30 queries per document daily, with a 11.71-second cold start
- Each query takes 5 seconds of processing time
Total Active Processing Time: (5 seconds * 3000 queries) / 3600 = approximately 4.1 hours
Cold Start Overhead: 11.71 seconds * 100 = 1171 seconds (or 0.32 hours)
Idle Time Between Queries: ((60 seconds - 5 seconds) * 3000) / 3600 = approximately 1.52 hours
Total Billable Hours with Inferless: 5.94 hours
Comparative Cost Analysis
By opting for Inferless, you can achieve up to 84% cost savings, lowering your operational expenses from $57.6 to just $9.47.
Please note, the above analysis is based on a smaller-scale scenario for demonstration purposes. Should the scale increase tenfold, traditional cloud services might require maintaining 2-4 GPUs constantly active to manage peak loads efficiently. In contrast, Inferless, with its dynamic scaling capabilities, adeptly adjusts to fluctuating demand without the need for continuously running hardware.
Discover the difference with real-world examples